오늘은 실제 엑셀데이터를 가저와서 전처리 해보는 시간을 가져보겠습니다.
데이터 확인


오늘 우리가 처리할 데이터 형태를 보면 여러 문제가 있습니다
- 정돈된 데이터가 아닌 컬럼이 독립적이지 않고 날짜 데이터가 컬럼별로 다르게 나와 있습니다.
- 컬럼명이 명시되어 있지 않습니다.
이러한 데이터를 어떻게 전처리 할지 한 번 알아 보겠습니다.
엑셀 데이터 불러오기

pandas 라이브러리를 통해 엑셀 데이터를 가져와 보았습니다

역시 데이터 정리가 되어있지 않네요
3. 데이터 전처리
위 데이터는 제품명이 키값으로 되어있는 데이터이다.
따라서 제품명을 기준으로 날짜 데이터를 처리해주면 될 것 같습니다.
3-1. 행 제거 후 가져오기
데이터를 살펴보면 2행에 컬럼명이 명시되어 있네요
이럴 때는 데이터를 가져올 때 2행부터 가저와주면 되겠습니다
skiprows 함수 사용

다음 여러 컬럼으로 나누어진 날짜 데이터를 하나의 컬럼으로 합쳐보는게 좋을 거 같습니다.
3-2. 날짜데이터 컬럼

데이터들의 컬럼을 확인 해보니 위와같이 나와있습니다
9번째 있는 판매 부터 마지막에서 2번째 앞 컬럼까지를 하나의 컬럼으로 만들어 주겠습니다
iloc 함수
index location 이라고 불리는 함수는 index를 기준으로 row들을 가져오는 함수 입니다.
' , ' 를 기준으로 앞엔 인덱스 뒤엔 컬럼을 가져오는 형식으로도 사용할 수 있습니다
ex) df1.iloc[ : , 8 : ] -> 8번째 컬럼부터 마지막 컬럼까지의 모든 인덱스를 가져온다.

이렇게 iloc 함수를 이용하여 특정 컬럼과 인덱스에 있는 데이터들을 가져왔습니다
우리가 원하는건 날짜데이터에 따라 데이터가 쭉 정렬 되는 것을 원합니다
이제 이 데이터들의 행과 열을 바꾸어 주겠습니다.
방법 1. Transpose 함수
가져온 데이터뒤에 Transpose 함수를 사용하여 행과 열을 바꿔준다

하지만 이 방법을 사용하게 되면 인덱스가 날짜로 갈 뿐 데이터가 그냥 일열로 쭉 나열된 것을 볼 수 있습니다.
방법 2. stack 함수

날짜에 맞게 하나의 컬럼으로 데이터가 나열된 것을 볼 수 있다.

이렇게 데이터 프레임으로 변환 후 데이터를 살펴 보니 날짜 데이터들이 값이 아닌 인덱스로 들어간 것을 볼 수 있다.
인덱스 되어있는 컬럼들을 밖으로 빼어내 주자
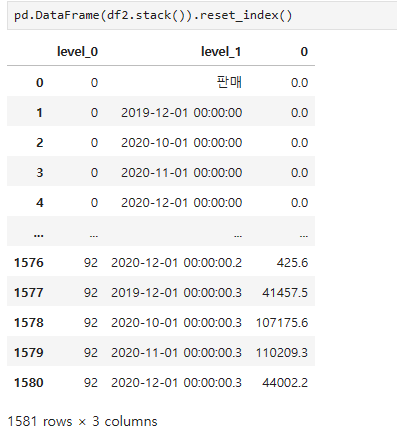
reset_index 함수를 사용하여 인덱스를 재 정렬 해주었다
이제 날짜데이터를 재 정렬 시키는 방법을 알았으니 제품명을 포함하여 나타내어 보자

drop 함수를 사용하여 제품명과 날짜 사이의 불 필요한 컬럼들을 삭제해준후 데이터를 보니 제고량 만 value 값으로 들어가야하는데 제품명도 값으로 들어간 것을 볼 수 있다
이러한 문제를 해결하기 위해 stack을 사용해주기 전 제품명을 index로 바꾸어주자

이제 stack 함수를 사용해도 '제품명'이 value 값으로 들어가지 않게 됩니다.

다시 reset_index 함수를 사용하여 제품명을 index에서 빼주겠습니다 .

이제 우리가 원하던 키값이 날짜 형태로 각 물품에 대한 재고량이 어떻게 되는지 알 수 있게 되었다
참고 : 파이썬 판다스로 회사 엑셀데이터 전처리 하는 방법 ! 1탄 (Python / Pandas) #Python #파이썬 #Pandas - YouTube



