엑셀 데이터 전처리를 이어서 진행 해보겠습니다.
데이터

오늘 전처리할 데이터는 음료회사의 점포, 상품, 수량으로 이루어진 데이터 이다
오늘 목표는
- 점포 별 판매량의 추이를 그래프로 표현
- 상품의 종류를 나누어 표현
- 가장 많이 팔린 점포만 확인
입니다
데이터 재구조화 및 전처리
- 원본 데이터의 구조를 바꾸어 주는 것
- pivot(), pd.pivot_table()
- stack(), unstack()
- melt()
- wide_to_long
먼저 필요없는 컬럼인 '순번', '상품코드' 컬럼을 삭제 해준 후 상품명을 기준으로 각 점포별 수량을 볼 수 있게 재구조화 해주겠습니다.
1. Stack 함수
상품명을 index로 둔 다음 stack 함수를 이용하여 전처리
- '상품명'을 index로 둔 이유는 value값에 수치 데이터만 남기기 위해서!
인덱스는 그대로 있는 상태에서 컬럼에 있는 값들이 value로 가고 그에 상응하던 value들이 또 하나의 value값으로 이동 되게 해준다.
다시 reset_index를 해주어 상품명을 밖으로 빼주자
2. Melt 함수
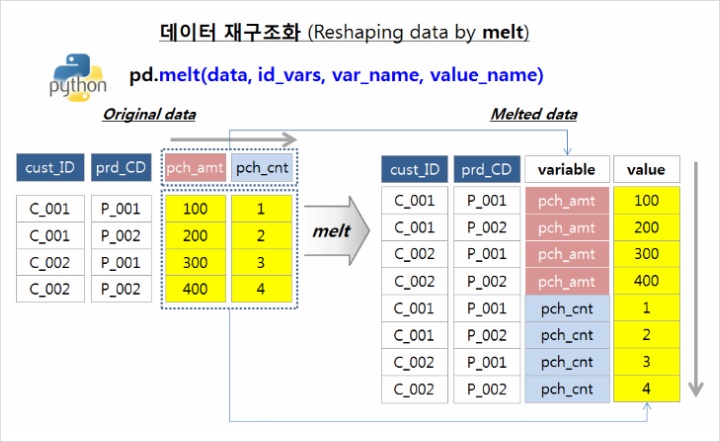
유지하고 싶은 column인 '상품명' 을 id_vars로 두고 점포명들을 values_vars 로 두어 진행

우리가 필요한 컬럼인 점포명은 4번 째 부터 있으므로 위 컬럼명들을 리스트 형태로 변환하여 4~마지막 까지를 가지는 리스트를 만들어 준 후 사용해준다
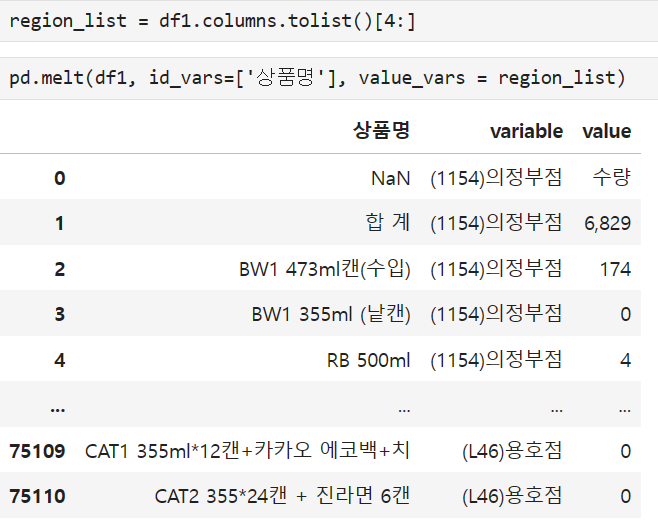
이제 가져온 데이터들에 필요 없는 행들을 가져오지 않으면서 인덱싱을 해주겠습니다.
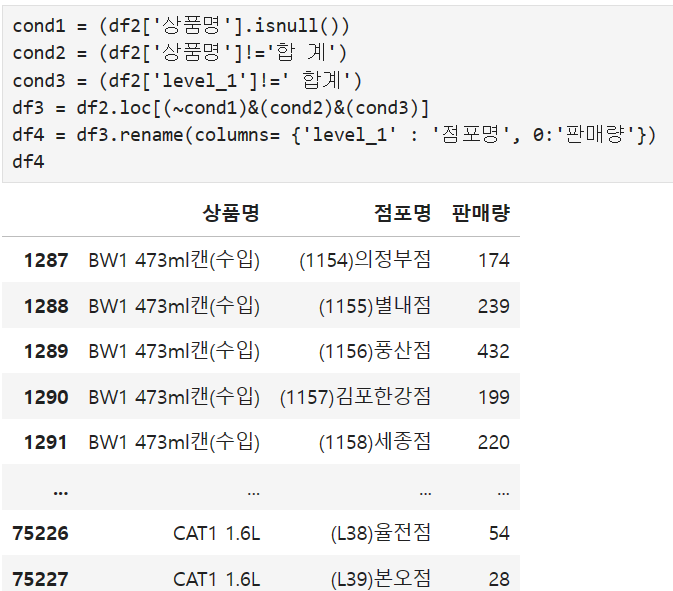
오늘 전처리해준 데이터를 가지고 다음 시간부터 분석을 해보겠습니다.
참고 : Pandas를 이용한 회사에서 나오는 엑셀 데이터 처리 (Stack / Melt) #Python #파이썬 (youtube.com)
,


