안녕하세요 이번시간에는 머신러닝에 대해서 가볍게 한 번 알아보겠습니다.
머신러닝이란 ?
- 인공지능(AI)를 구현하는 방법 중 하나로 빅데이터를 기계 스스로가 분석(학습)하고, 분석한 내용을 통해 결론(수식)을 도출하는 기술이다.
이처럼 학습 결과로 얻어진 지능을 이용하여 분석하고 사용하는 기술을 '머신러닝(Machine Learning)' 이라고 합니다.
- 머신러닝 핵심 3 요소
- 데이터 : 학습 목적에 맞는 데이터 셋 구축
- 알고리즘 : 학습 목적에 맞는 적절한 알고리즘 선택 ex) 선형 회귀분석 / 의사 결정 나무 / KNN / SVM ....
- 하드웨어 : CPU / GPU
- Scikit Learn
- 파이썬에서 머신러닝을 할 수 있게 도와주는 라이브러리
- 정형데이터를 처리하는 Pandas 와의 상호작용이 유연하다
- 데이터 마이닝
- Machine Learning 종류
- 지도학습 (Supervised Learning) : 목표변수(Y)와 설명변수(X)간의 관계를 수식화 하여, 새로운 설명변수(X)에 대해 목표변수(Y)를 예측하거나 분류하는 기법
- 비지도 학습 (Unsupervised Learning) : 설명변수(X)들 간의 관계/연관성등을 파악하여 비슷한 데이터끼리 군집화 / 연관성 있는 데이터를 묶는 기법
- 강화 학습 (Reinforcement Learning) : 주어진 환경에서 자신이 한 행동에 대한 보상이 좋은 방향으로 학습하는 기법
데이터 마이닝
- 데이터로 패턴이나 규칙을 찾아 실무에 적용할 수 있는 insight를 발견하는 방법론
데이터 마이닝 문제해결 Process : KDD / SEMMA ...
- 데이터 준비 - Target(목표 변수) : 어떤 Y에 대해서 패턴을 찾겠는가 / X (feature 설명변수) : 제품명, 판매일자, 요일 ..
- 데이터 전처리 - 좋은 학습을 할 수 있는 환경을 만들어 주는 구간. 학습 / 평가 데이터를 나눠주고, 데이터를 다듬어주는 구간(결측치, 이상치 등의 처리)
- 데이터 학습 ( 모델을 만드는 것) - 학습데이터를 알고리즘(회귀분석, Tree, SVM등 ..) 을 이용하여 모델 도출
- 모델 평가 - 평가 데이터들로 모델 평가
보통 전체 데이터의 7~80% 데이터(학습 데이터)로 학습을 통해 모델을 얻고 남은 2~30% 데이터들(평가 데이터)로 모델을 평가 한다.
ex) 매출 정보 데이터를 통해 다음달에 매출액이 어떨지 예측 해보고 싶다
-> 기존에 있던 매출액 데이터를 학습시켜 다음달에 매출이 어떻게 될 지 추측 하는 것
그럼 실제 데이터를 통해 연습을 해보겠습니다.
실제 데이터 활용

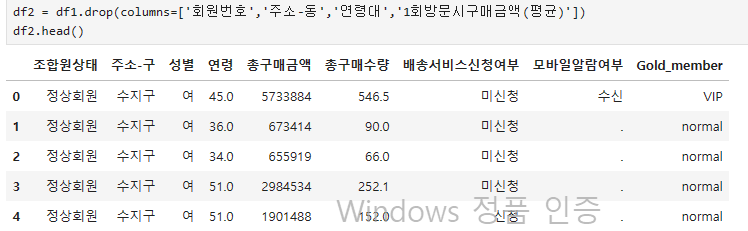
위 데이터는 실제 마켓의 회원정보 데이터 이다.
회원번호가 키값으로 회원번호에 따라 데이터가 나열되어 있다.
오늘 해볼 예측은 회원의 Gold_member을 타겟(Y)으로 분석을 해보겠습니다.
1. 데이터 준비 및 가공 ( Pandas 사용)
- Y (Target) : Gold_member / X (feature) 설명변수
- 변수선택 (feature Selection) - 변수 선택을 통해 불 필요한 데이터를 삭제하거나 처리해줌
- 결측치(Missing Value) 처리

isnull 함수에 sum 함수를 사용하여 결측치를 확인 해주었다.

dropna 함수를 이용하여 결측치를 제거 해주었다.
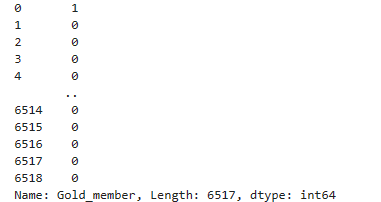
- 타겟변수 가공
먼저 Target 변수의 데이터를 확인해주자

데이터는 범주형 자료로 수치형 데이터로 바꾸어 줘 보겠다

replace({'컬럼명' : 값, '컬럼명2' : 값 ,...}) replace 함수를 통해 변경
이처럼 가지고 있는 컬럼 중 범주형 데이터를 수치형으로 변환 시켜주는 '원핫 인코딩' 처리를 해주겠습니다
원핫 인코딩(One-hot Encoding) : 단순히 수치형 데이터로만 바꾸게 되면 서로 간의 관계성이 생기기 때문에 서로 무관한 수로 변환 하여 위같은 문제를 막아주는 변환 법.
get_dummies 함수를 사용하여 원핫 인코딩을 해준후 X,Y 값 지정해주자

2. 데이터 전처리(분할 / Sklearn
- 오늘 사용할 sklearn 기능 함수
- Model_selection - 데이터 분할
- metrics - 데이터 평가
- preprocessing - 스케일링
- tree - 알고리즘 종류
- 등등
2-1 . 데이터 분할

sklean 이라는 라이브러리 내에 model_selection 이라는 모듈의 train_test_split 이라는 함수를 가져온다는 의미

train_test_split gkatn - 데이터를 분할 해주는 함수
데이터 분할이 적절하게 잘 된 것을 shape으로 확인해주었다.
2-2 . 학습
이제 학습 데이터 셋으로 학습을 시켜주자
우리는 의사결정나무(DecisionTree)를 사용 할 것이다 .
의사결정 나무란 ?
if ~ else 처럼 특정 조건을 기준으로 True / False 로 나누어 분류 및 회귀를 진행하는 tree 구조의 분류 / 회귀 데이터 마이닝 기법

종속변수가 범주형 - DecisionTreeClassifier 으로 분류
종속변수가 연속형 - DecisionTreeRegression 으로 회귀
fit - 데이터를 입혀주는 함수 즉 학습을 시킴
즉 Tree라는 알고리즘에 의해서 넣어준 데이터셋에 맞게 분류 모델(수식)을 도출 해내었다.
2-3 . 모델 평가
도출된 모델을 평가 해보겠습니다.
평가 종류 (학습과 일반화)
1. 학습 : 알고리즘이 모델을 얼마나 학습을 잘 시켰는가? -> X_train 데이터로 예측.
2. 일반화 : 새로운 데이터 가 들어올 때, 얼마나 좋은 성능을 나타내는가? -> X_test 데이터로 예측

평가 방법
기존에 모델 도출에 사용된 X_train 데이터와 X_test 데이터를 모델에 집어넣어 예측된 종속변수 값(컴퓨터에 의해 예측 된 값)을 얻어 기존의 종속변수 값과 비교해보겠습니다.
ex)
| VIP(예측) | 얻어진 모델에 데이터를 넣어줌 ----------------------------------> predict 함수 사용으로 예측 |
VIP(예측) |
| 0 | 0 | |
| 1 | 0 |
classification_report 함수를 이용

위 결과를 분석해본 결과 학습은 잘 되었지만 새로운 데이터에 대한 일반화 능력은 떨어지는 것을 볼 수 있다.
-> 데이터 전처리가 잘못 되었을 경우, 맞지않는 알고리즘을 사용한 경우
참고 : [매일10분 데이터 분석] 파이썬 머신러닝 맛보기 1탄 (Scikit Learn 이해하기 ) #Python #파이썬 (youtube.com)
[매일10분 데이터 분석] 파이썬 머신러닝 맛보기 2탄 (Scikit Learn 사용해보기) #Python #파이썬 (youtube.com)
[매일10분 데이터 분석] 파이썬 머신러닝 맛보기 3탄 ( 학습을 잘했는지 평가하기 ) #Python #파이썬 (youtube.com)


