이번 시간에는 Transfermarkt 사이트에서 실제 축구선수의 시장가치 분석을 위한 크롤링을 해보겠습니다.
실전 크롤링
먼저 크롤링에 필요한 라이브러리를 가져오겠습니다

그 후 우리가 분석할 https://www.transfermarkt.com/spieler-statistik/wertvollstespieler/marktwertetop 웹 사이트의 정보를 request를 통해서 불러오겠습니다!
Requests

응답으로 200이 온 것으로 보아 올바른 응답이 왔음을 알 수 있습니다.
BeautifulSoup을 통해 분석 준비를 해보겠습니다
BeautifulSoup

soup의 정보를 보니 url의 html 정보가 잘 담긴 것을 볼 수 있습니다.
선수들의 정보가 담긴 태그와 클래스 찾고 가져오기
이제 선수들의 정보가 담긴 태그와 클래스를 찾아 BeautifulSoup를 통해 불러와 보겠습니다.

위 url에서 찾아보니 태그는 tr , class 는 odd 와 even 으로 되어있는 것을 볼 수 있습니다.
그럼 선수들 정보를 가져와보겠습니다.
class 명이 'odd', 'even' 둘 다 가져와야 하기 때문에 리스트 형태로 가져오 주겠습니다.

첫 번째 선수인 'Jude Bellingham' 선수의 정보가 잘 가져와 진것을 볼 수 있습니다.

.

선수들의 정보는 'td'태그에 담겨있는것을 알 수 있다.
player_info에 있는 리스트들에서 'td' 태그를 빼와보자

가져온 'td'태그들 리스트에 0번 째의 순서를 확인 해보니 각 선수들의 순위가 나타나 있다
이제 가져온 td 태그 안에 있는 숫자들을 리스트 형식으로 빈 리스트에 넣어주자

선수들의 순위가 잘 담긴것을 볼 수 있다
이제 선수들에 정보를 다 가져오자

데이터 저장하기
pandas 라이브러리를 이용하여 DataFrame형식으로 데이터를 저장하겠다.

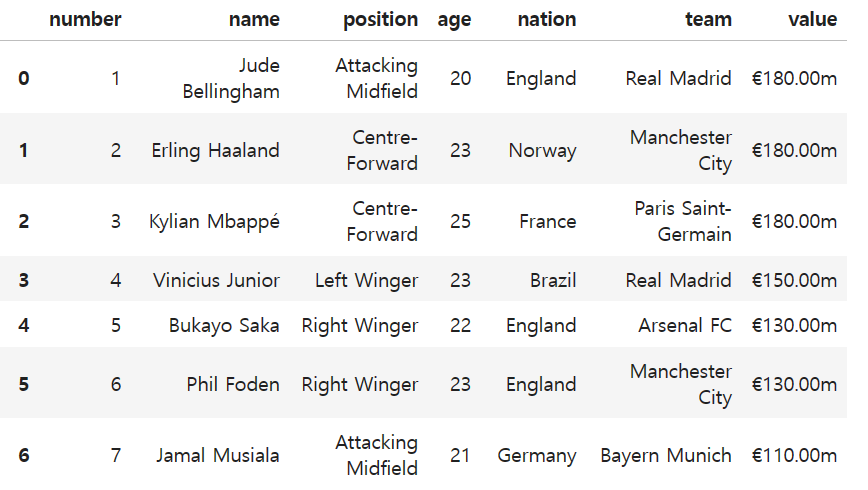
df1.to_csv('transfermarkt25.csv', index = False)로 데이터를 파일로 저장하면 된다.
2번 째 페이지 동시에 크롤링 하기


1 페이지와 2 페이지의 url이 마지막에 숫자 하나가 다른 것을 알 수 있다.

url에 f-string 문법을 적용하여 반복문(범위를 2로 하여 1,2 페이지만 크롤링 하게끔) 안에 넣고 위와 동일한 크롤링 과정들을 반복문 안에 작성 해주면 된다.
여기서 주의할 점은 선수들의 정보를 담을 빈 리스트는 반복문 밖에 빼놔야 반복문이 실행 될 때 마다 리스트가 초기화 되는 문제를 해결 할 수 있다
참고 : https://www.youtube.com/watch?v=_8dIyKbGve0&list=PL13IrJom4GzssqejzOqR2S0OukBIyufjy&index=5
https://www.youtube.com/watch?v=F-ZcXMacKlY&list=PL13IrJom4GzssqejzOqR2S0OukBIyufjy&index=6
